😁Address Handle
前面已经介绍过,RDMA通信的基本单元是QP。我们来思考一个问题,假设A节点的某个QP要跟B节点的某个QP交换信息,除了要知道B节点的QP序号——QPN之外,还需要什么信息?要知道,QPN是每个节点独立维护的序号,不是整个网络中唯一的。比如A的QP 3要跟B的QP 5通信,网络中可不止一个QP5,可能有很多个节点都有自己的QP 5。所以我们自然可以想到,还需要找到让每个节点都有一个独立的标识。
在传统TCP-IP协议栈中,使用了家喻户晓的IP地址来标识网络层的每个节点。而IB协议中的这个标识被称为GID(Global Identifier,全局ID),是一个128 bits的序列。关于GID本篇不展开讨论,将在后面介绍。
AH是什么
AH全称为Address Handle,没有想到特别合适的中文翻译,就先直译为“地址句柄”吧。这里的地址,指的是一组用于找到某个远端节点的信息的集合,在IB协议中,地址指的是GID、端口号等等信息;而所谓句柄,我们可以理解为一个指向某个对象的指针。
大家是否还记得IB协议中有四种基本服务类型——RC、UD、RD和UC,其中最常用的是RC和UD。RC的特点是两个节点的QP之间会建立可靠的连接,一旦建立连接关系便不容易改变,对端的信息是创建QP的时候储存在QP Context中的;
而对于UD来说,QP间没有连接关系,用户想发给谁,就在WQE中填好对端的地址信息就可以了。用户不是直接把对端的地址信息填到WQE中的,而是提前准备了一个“地址薄”,每次通过一个索引来指定对端节点的地址信息,而这个索引就是AH。
AH的概念大致可以用下图表示:
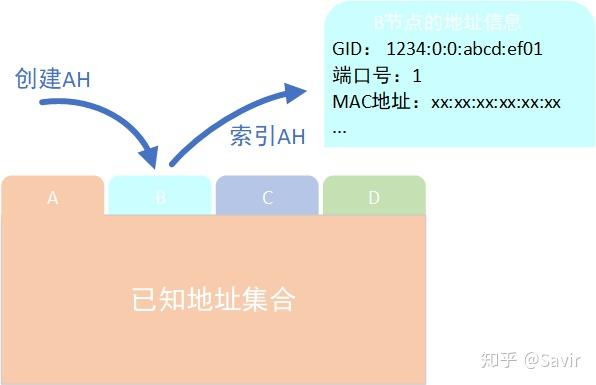
对于每一个目的节点,本端都会创建一个对应的AH,而同一个AH可以被多个QP共同使用。
AH的作用
每次进行UD服务类型的通信之前,用户都需要先通过IB框架提供的接口,来为每一个可能的对端节点创建一个AH,然后这些AH会被驱动放到一个“安全”的区域,并返回一个索引(指针/句柄)给用户。用户真正下发WR(Work Request)时,就把这个索引传递进来就可以了。
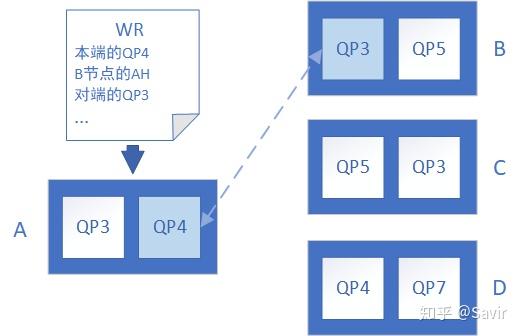
上述过程如下图所示,A节点收到用户的这样一个任务——使用本端的QP4与B节点(通过AH指定)的QP3进行数据交换:
IB协议中并没有对为什么使用AH做出解释,我认为定义AH的概念的原因有以下三种:
保证目的地址可用,提高效率
因为UD无连接的特点,用户可以在用户态直接通过WR来指定目的地。而如果让用户随意填写地址信息,然后硬件就根据这些信息进行组包的话,是会带来问题的。比如有这样一种场景:用户通过WR告诉硬件请给GID为X,MAC地址为Y的节点的端口Z发送数据。然而X,Y,Z可能不是一个合法的组合,或者GID为X的节点压根都不存在于网络中,而硬件是无力校验这些内容的,只能乖乖的组包、发送数据,这个目的地无效的数据包就白白发送出去了。
而提前准备好地址信息,则可以避免上述情况。用户在创建AH时会陷入内核态,如果用户传递的参数有效,内核会把这些目的节点信息储存起来,生成一个指针返回给用户;如果用户传递的参数无效,AH将创建失败。这一过程可以保证地址信息是有效的。用户通过指针就可以快速指定目的节点,加快数据交互流程。
可能有人会问,既然内核是可信的,为什么不能在发送数据时陷入内核态去校验用户传递的地址信息呢?请别忘了RDMA技术的一大优势在哪里——数据流程可以直接从用户空间到硬件,完全绕过内核,这样可以避免系统调用和拷贝的开销。如果每次发送都要检验地址合法性的话,必然会降低通信速率。
2. 向用户隐藏底层地址细节
用户创建AH时,只需要传递gid、端口号、静态速率等信息,而其他通信所需的地址信息(主要是MAC地址)是内核驱动通过查询系统邻居表等方式解析到的,底层没有必要暴露这些额外的信息给用户层。
3. 可以使用PD对目的地址进行管理
前文我们介绍保护域时曾经提过,除了QP、MR之外,AH也由PD来进行资源划分。当定义了AH这个软件实体之后,我们就可以对所有的QP可达的目的地进行相互隔离和管理。
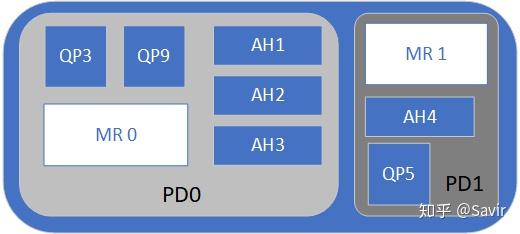
比如上图中,AH1~3只能被同一个PD下的QP3和QP9使用,而AH4只能被QP5使用。
协议相关章节
协议中关于AH的篇幅并不多,甚至没有独立介绍其概念的章节:
[1] 9.8.3 UD服务类型中的目的地址由哪些部分组成:包括AH、 QPN和Q_key
[2] 10.2.2.2 目的地址的相关注意事项
[3] 11.2.2.1 AH相关的Verbs接口
AH就介绍到这里,感谢阅读。下一篇打算向大家描述更多关于QP的细节。
Last updated