😅RoCE
RDMA之RoCE & Soft-RoCE
我们知道,支持RDMA的网卡都比较昂贵,拿Mellanox(现在是NVIDIA)来说,在其官网上最新一代支持Infiniband的网卡——ConnectX-6最便宜的单端口型号也要795刀,这对于我们学生来说是一笔不小的开销。
RDMA技术实际应用的话是得依赖网卡来完成大部分工作的,但是好在我们有Soft-RoCE。它通过软件代替硬件来将IB传输层的报文加在普通UDP报文中,从而得以让普通网卡也可以发送RoCE报文,这对于为我们学习IB传输层协议,以及编写调试基于Verbs的RDMA程序提供了一种非常低成本的方案。
本篇文章将介绍RoCE是什么、它的由来以及Soft-RoCE的实现原理等。
RoCE全称是 RDMA over Converged Ethernet,即基于融合以太网的RDMA。
用通俗的话讲,就是基于传统以太网的部分下层协议,在其基础上实现Infiniband的部分上层协议。
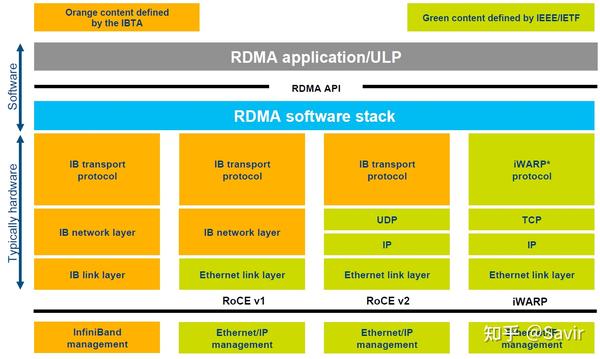
RoCE的协议层次
下面这张图之前出现过,它比较清晰的划分出了这几种协议的关系:
可能还不够直观,我们把RoCE v2的一个报文展开来看(没有画出物理层协议):
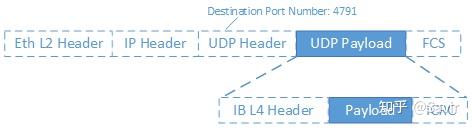
首先是二层的以太网链路帧,然后是IP报文头和UDP报文头,最后是各层级协议的校验。而Infiniband传输层报文实际上是UDP层的负载,也就是深蓝色背景的部分。UDP报文头中有一个字段Destination Port Number(目的端口号),对于RoCE v2来说固定是4791,当对端网卡收到报文后,会根据该字段识别是普通的以太网数据包,还是RoCE数据包,或者是其他协议的数据包,然后再进行解析。深蓝色背景的IB传输层部分又分成了IB报头,实际的用户数据(Payload)以及校验部分。IB传输层实际上有很多种报头以及对应的格式,我们以后再介绍。
为什么我们有了Infiniband协议之后,还要设计RoCE协议呢?最主要的原因还是成本问题:由于Infiniband协议本身定义了一套全新的层次架构,从链路层到传输层,都无法与现有的以太网设备兼容。也就是说,如果某个数据中心因为性能瓶颈,想要把数据交换方式从以太网切换到Infiniband技术,那么需要购买全套的Infiniband设备,包括网卡、线缆、交换机和路由器等等。商用级设备由于对可靠性有比较高的要求,所以这一套下来是非常昂贵的。
而RoCE协议的出现解决了这一问题,如果用户想要从以太网切换到RoCE,那么只需要购买支持RoCE的网卡就可以了,线缆、交换机和路由器(RoCE v1不支持以太网路由器)等网络设备都是兼容的——因为我们只是在以太网传输层基础上又定义了一套协议而已。
所以RoCE相比于Infiniband,主要还是省钱,当然性能上相比Infiniband还是有一些损失,毕竟人家是全套重新设计的。
至于iWARP,相比于RoCE协议栈更复杂,并且由于TCP的限制,只能支持可靠传输,即无法支持UD等传输类型。所以目前iWARP的发展并不如RoCE和Infiniband。
Soft-RoCE
虽然RoCE相比Infiniband具有兼容性优势,价格也便宜,但是实际应用的时候依然需要专用的网卡支持。有的读者可能会问,TCP/IP协议栈不是由软件实现的吗,只是在UDP层基础上加了层内容,为什么会对硬件有依赖?
RoCE本身确实可以由软件实现,也就是本节即将介绍的Soft-RoCE,但是商用的时候,几乎不会有人用软件实现的RoCE。RDMA技术本身的一大特点就是“硬件卸载”,即把本来软件(CPU)做的事情放到硬件中实现以达到加速的目的。CPU主要是用来计算的,让它去处理协议封包和解析以及搬运数据,这是对计算资源的浪费。所以RoCE网卡会把TCP/IP协议栈放到硬件中实现以解放CPU,让它去做更重要的事。
我们说回Soft-RoCE,它由IBM和Mellanox牵头的IBTA RoCE工作组实现。本身的设计初衷有几点:
降低RoCE部署成本
Soft-RoCE可以使不具备RoCE能力的硬件和支持RoCE的硬件间进行基于IB语义的交流,这样可以免于替换网络中的一些非关键节点的旧型号网卡。
相比TCP提升性能?
虽然软件实现IB传输层带来了一定的开销,但是相比基于Socket-TCP/IP的传统通信方式,Soft-RoCE因为减少了系统调用(只在软件通知硬件下发了新SQ WQE时才会使用系统调用),发送端的零拷贝以及接收端的只需要单次拷贝等原因,仍然带来了性能上的提升?。
注意:根据网友们的反馈以及我自己实测,Soft-RoCE的性能不及TCP。主要是几个原因: 1. IB传输层MTU最大为4096,256 Bytes的Header + 4096 Bytes的Payload,Header所占比例较高;而TCP的MTU可以很大,相当于提高了有效载荷。 2. 网卡往往可以为TCP提供硬件加速功能。 3. Soft-RoCE用CPU去计算CRC,这是一件很慢的事情。 这里提供我能想到的提升性能的思路: 1. 在编程时做多线程,每个线程绑定一个核,并且每个线程间不要共享使用QP,因为会出现抢锁。 2. 使用WR List代替单个WR,即每次Post Send时下发多个WR组成的WR链表,减少敲Doorbell时的系统调用开销。 3. 将网卡的MTU值设置为大于4096 + 256,可以避免链路层切包的开销。 4. 如果是RXE对接测试,可以通过修改RXE驱动关闭CRC校验,并提高RoCE的MTU值,但是这样违反了协议,貌似没什么意义。 附社区讨论该问题的链接:Soft-RoCE performance - Christian Blume (kernel.org)
便于开发和测试RDMA程序
有了Soft-RoCE,我们基于Verbs API编写的程序,就可以不依赖于硬件执行起来,也可以很方便的跑在虚拟机里。
实现原理
Soft-RoCE就是把本来应该卸载到硬件的封包和解析工作,又拿到软件来做。其本身是基于Linux内核的TCP/IP协议栈实现的,网卡本身并不感知收发的数据包是RoCE报文,其驱动程序按照IB规范中的报文格式将用户数据封装成IB传输层报文,然后把报文整体当做数据填入Socket Buffer当中,由网卡进行下一步收发包处理。
下面这张图取自IBTA对于Soft-RoCE的介绍文章,左边是需要硬件的普通RoCE,右边是Soft-RoCE。可以看出普通RoCE是把协议栈卸载到RoCE NIC网卡实现的,而Soft-RoCE则是在软件协议栈中实现的。

Last updated