# 用户态与内核态交互
在“[**Verbs**](https://rookiedong.gitbook.io/notes/dpu-and/rdma/verbs)”一文中我一文中我们说道,Verbs API分为用户态和内核态,分别以ibv\_和ib\_作为前缀。RDMA技术的最大的优势就在于用户态可以绕过内核,直接控制硬件收发数据,减少了系统调用和内存拷贝次数,所以大部分的RDMA应用都是用户态应用,即使用以ibv\_为前缀的用户态Verbs API。
但是并非所有的用户态Verbs API都可以完全绕开内核,本文中我来讲解一下哪些API依赖于内核RDMA子系统(包括驱动),为什么需要依赖内核,以及用户态和内核是如何交互的。
### Verbs的分类
IB规范11.1.2.3节中将Verbs的用户分成两种:一种是能够直接访问OS内部数据和控制RDMA硬件的特权用户,他们能使用所有Verbs;一种是必须依赖代理来访问OS数据结构的用户层用户,他们只能使用一小部分的Verbs。
翻译成直白点的话,就是内核态的Verbs用户由于拥有最高权限,所以直接访问所有RDMA资源;而用户态的Verbs用户,只能使用部分接口直接与硬件交互,而大部分Verbs API需要通过系统调用等方式进入内核态来完成。
IB规范中的Table 95列出了所有Verbs的实现必要性和需要的用户权限。实现必要性上,Mandatory表示软件必须支持,其他表示软件可以选择性的支持;用户权限上,Privileged表示需要特殊权限,User-Level表示仅需要普通权限。
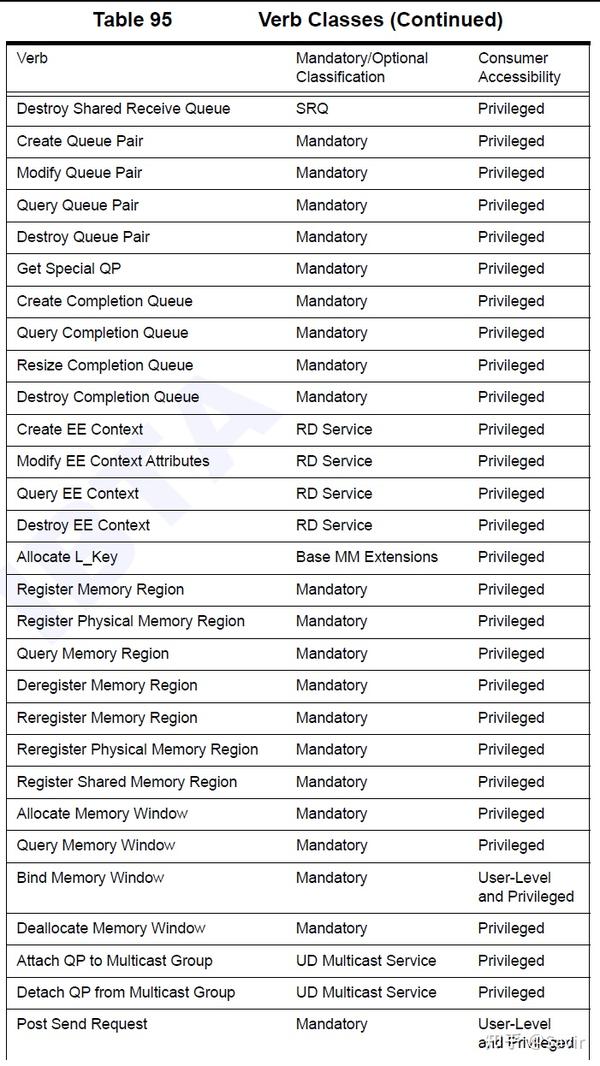 通过观察表格我们可以发现,除了下发WR(Post Send和Post Recv)和获取WC(Poll CQ和Request Completion Notification)这种用于数据交互的接口,以及Bind MW和AH的相关操作,其他所有操作都需要特权,即调用对应的Verbs API都需要陷入内核态。
### RDMA软件协议栈
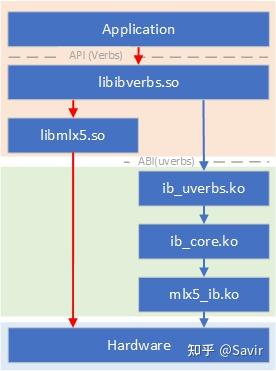
为了便于后文的说明,我们这里以Mellanox的驱动为例,给出RDMA软件栈的粗略架构,以后的文章会更详细的描述这一部分。
通过观察表格我们可以发现,除了下发WR(Post Send和Post Recv)和获取WC(Poll CQ和Request Completion Notification)这种用于数据交互的接口,以及Bind MW和AH的相关操作,其他所有操作都需要特权,即调用对应的Verbs API都需要陷入内核态。
### RDMA软件协议栈
为了便于后文的说明,我们这里以Mellanox的驱动为例,给出RDMA软件栈的粗略架构,以后的文章会更详细的描述这一部分。
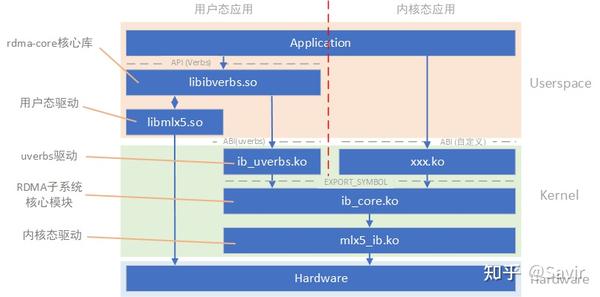 首先从上往下看:
#### 用户空间
* Application\
各种RDMA应用程序(比如perftest)、中间件(比如UCX)等。
首先从上往下看:
#### 用户空间
* Application\
各种RDMA应用程序(比如perftest)、中间件(比如UCX)等。
* libibverbs.so\
RDMA软件栈用户态核心动态链接库,作用:
1. 实现并且向上层应用提供各种Verbs API
2. 在各种Verbs API的逻辑中调用到各厂商驱动注册的钩子函数
3. 提供进入内核态的接口
* libmlx5.so\
Mellanox ConnectX-5网卡的用户态驱动,也是个动态链接库,实现厂商的驱动逻辑。
#### 内核
* 中间交互模块\
负责通过ABI来处理用户态的系统调用请求,用户态verbs陷入内核,需要通过这一层的ib\_uverbs模块来解析命令;另外右侧的xxx.ko指的是使用内核verbs接口(比如ib\_post\_send)的上层应用程序所需要的处理系统调用的自定义模块。
* ib\_core.ko\
内核RDMA子系统核心模块,作用:
1. 向使用内核态Verbs的应用程序提供内核态Verbs API
2. 在各种Verbs API的逻辑中调用到各厂商驱动注册的钩子函数
3. 管理各种RDMA资源,为用户态提供服务
* mlx5\_ib.ko\
Mellanox ConnectX-5网卡的内核态驱动模块,负责直接和硬件交互。
* 硬件\
指Mellanox ConnectX-5网卡。
然后我们以红色虚线为界分左右来看这张图,左侧是用户态应用程序的层次结构,右侧为内核态应用程序的层次结构。其中用户态应用又分为左右两条路,左边绕过内核的是指数据路径,右边需要通过内核的是指控制路径。
**注意,严格来讲“内核态应用”这个说法是不正确的,因为应用都是运行在用户态的,这里的内核态应用指的是指通过中间模块间接使用内核Verbs API的应用程序,区别于使用用户态Verbs API的大部分RDMA应用程序**。
### 为什么需要陷入内核态
正如本文第一节所述,控制路径上的操作都需要陷入内核态,而数据路径上的操作一般都不需要陷入内核态。为什么有的Verbs非要陷入内核态执行呢,主要有两种原因:
**1) 用户态是不安全的,有些资源不能暴露给用户态修改**
用户态的so是可以被普通用户替换的,即rdma-core的组件,包括libibverbs,librdmacm以及用户态驱动的代码都是可以被修改的。如果把RDMA资源暴露给用户态,比如内核QP结构体的指针,或者其配置信息QPC的地址,则可能被没有遵守IB规范编写应用程序的用户,甚至恶意用户篡改关键信息,引发安全问题。所以用户态只能拿到RDMA资源的句柄(handle),在与内核通信的过程中,内核通过idr机制还原出具体的QP指针,进行后续的操作。
此外内核可以跟踪各种RDMA资源的使用情况,在用户态程序异常退出时也可以释放这些资源。
**2) 需要建立虚拟地址到物理地址的静态映射**
因为用户态IO是在WR中指定虚拟地址直接下发到硬件的,这就需要硬件能够找到用户虚拟地址所对应的内存物理地址。在注册MR的过程中,内核驱动会为硬件建立地址映射表。而为了防止换页导致的虚拟-物理地址映射关系发生改变,内核驱动会触发pin的动作,即固定这个映射关系。
陷入内核态的动作,具体来说是通过系统调用,从用户上下文切换到内核上下文,这期间涉及到进程切换和权限检查等等动作,会有一定的时间开销。
而有些Verbs没有上述限制,比如通过直接读写映射到用户态的硬件寄存器来下发WQE,是不需要修改RDMA资源或者对内存映射进行管理的,那么自然就不需要陷入内核。这就是RDMA技术的优点之一,即在数据路径上bypass内核。相比传统的Socket数据交互,这样可以节省下用户每次收发数据时在内核和用户态间来回切换的时间。
正是因为陷入内核的开销,有人也将需要陷入内核态的Verbs路径为“慢路径”,不需要陷入内核的为“快路径”。
### 用户态和内核态如何交流
控制路径上,用户态和内核态主要是通过write()系统调用来对/dev/infiniband/uverbsN字符设备文件进行操作的,从而实现交流信息的。最近的协议栈也支持了ioctl()系统调用,但是笔者还没怎么研究过,所以不在本文讨论了。为了说明用户态和内核态是如何交流的,大家需要区分两个概念——API和ABI:
#### API
我们称程序之间的编程接口为API(Application Programming Interface),Verbs接口就是一套API。比如我们写的一个应用程序里面有一段代码是这样写的:
```c
#include
int send_message(struct msg *)
{
...
struct ibv_qp *qp = ibv_create_qp(pd, init_attr);
...
}
```
因为verbs.h头文件里面ibv\_create\_qp()接口的定义(名称,参数和返回值)在各个版本的verbs库中都没有改变:
```c
/**
* ibv_create_qp - Create a queue pair.
*/
struct ibv_qp *ibv_create_qp(struct ibv_pd *pd,
struct ibv_qp_init_attr *qp_init_attr);
```
所以我们写的这个**程序的源码不需要任何修改,就可以基于任何版本的用户态库(rdma-core)进行编译,得到可执行的应用程序文件**。
#### ABI
ABI(Application Binary Interface)是应用程序间的二进制接口,本文中RDMA软件栈架构图中的Userspace和Kernel之间的uverbs接口就是一种ABI。ABI定义了运行时的程序之间交流的格式,比如参数以什么形式传递(分别写到指定的寄存器/使用栈)、以什么格式传递以及返回值放到哪里等等。
uverbs API规定了用户态和内核态之间的命令消息cmd的格式和返回消息resp的格式,大致是下图这个意思:
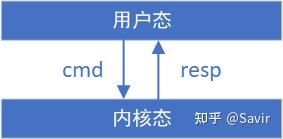 我们在“[RDMA之Verbs](https://zhuanlan.zhihu.com/p/329198771)”一文中介绍过用户态库和内核驱动,它们各自都按照自己的节奏发布版本,用户态和内核态之间交互,涉及到很多命令的传递,而不同版本之前的交互格式是有差异的。RDMA软件栈通过设计uverbs ABI接口来**保证不同版本的用户态和内核态之间的兼容性,即某个版本的用户态库,可以直接运行在各种版本的内核上**。
我们还是拿Create QP的动作来举例,软件栈中是这样ibv\_create\_qp()的定义cmd和resp的:
我们在“[RDMA之Verbs](https://zhuanlan.zhihu.com/p/329198771)”一文中介绍过用户态库和内核驱动,它们各自都按照自己的节奏发布版本,用户态和内核态之间交互,涉及到很多命令的传递,而不同版本之前的交互格式是有差异的。RDMA软件栈通过设计uverbs ABI接口来**保证不同版本的用户态和内核态之间的兼容性,即某个版本的用户态库,可以直接运行在各种版本的内核上**。
我们还是拿Create QP的动作来举例,软件栈中是这样ibv\_create\_qp()的定义cmd和resp的:
 可以看到cmd分为三个部分:
* 命令码:告诉内核态当前陷入内核态想要执行的操作
* 公共域段:所有厂商的创建QP动作都需要从用户态传递到内核态的参数
* 驱动自定义域段:各个厂商自定义的需要传递到内核的参数
可以看到cmd分为三个部分:
* 命令码:告诉内核态当前陷入内核态想要执行的操作
* 公共域段:所有厂商的创建QP动作都需要从用户态传递到内核态的参数
* 驱动自定义域段:各个厂商自定义的需要传递到内核的参数
 resp分为两个部分:
* 公共域段:所有厂商在内核创建完QP之后,需要返回给用户态的参数
* 驱动自定义域段:各个厂商的自定义返回参数
上面的格式都是由uverbs ABI接口定义的,具体来说整套用户态和内核的交互机制都是由内核的ib\_uverbs.ko和用户态的libibverbs.so相配合实现的。
实际上除了各个厂商的驱动开发者,RDMA应用程序开发者以及普通用户不必用关心ABI的实现,只需要关心API就可以了。
### 一个例子
下面我们把整个流程串起来看一下,当我们调用Verbs API之后发生了什么。
#### 需要陷入内核态的Verbs接口
需要陷入内核态的接口,走的是标红色箭头的“慢路径”:
resp分为两个部分:
* 公共域段:所有厂商在内核创建完QP之后,需要返回给用户态的参数
* 驱动自定义域段:各个厂商的自定义返回参数
上面的格式都是由uverbs ABI接口定义的,具体来说整套用户态和内核的交互机制都是由内核的ib\_uverbs.ko和用户态的libibverbs.so相配合实现的。
实际上除了各个厂商的驱动开发者,RDMA应用程序开发者以及普通用户不必用关心ABI的实现,只需要关心API就可以了。
### 一个例子
下面我们把整个流程串起来看一下,当我们调用Verbs API之后发生了什么。
#### 需要陷入内核态的Verbs接口
需要陷入内核态的接口,走的是标红色箭头的“慢路径”:
 #### ibv\_open\_device()
顾名思义,其作用打开设备,通俗的讲它主要完成了下面几件事:
* 创建设备上下文结构device\_context
这个结构可以理解成从软件角度看到的设备的实体,以后的程序中都用这个结构指代我们要使用的设备。
* 映射PCIe BAR空间,让用户获取到Doorbell的地址
这里面mmap的机制比较复杂,大意就是让用户能够直接读写网卡的某些寄存器来实现和硬件的交互。这些映射到用户空间的寄存器中,最重要的就是Doorbell。它其实就是门铃的意思。是一种通知机制,当用户准备好WR之后,向Doorbell的地址中写一下数据,就等于敲了一下门铃,硬件就知道可以把WQE从QP中取走然后开始干活了。
* 挂载回调函数到IB框架
因为各个厂商的硬件和软件实现都不一样,所以IB框架开放了很多钩子函数,根据不同的硬件型号,会走到不同厂商的驱动程序中。
* 查询设备能力
用户可以获知当前硬件支持的功能、规格等信息,比如支持创建多少个QP,多少个CQ等等。
这个过程的调用栈如下图所示,这里仅列出了关键函数,红色虚线表示从用户态陷入内核态:
#### ibv\_open\_device()
顾名思义,其作用打开设备,通俗的讲它主要完成了下面几件事:
* 创建设备上下文结构device\_context
这个结构可以理解成从软件角度看到的设备的实体,以后的程序中都用这个结构指代我们要使用的设备。
* 映射PCIe BAR空间,让用户获取到Doorbell的地址
这里面mmap的机制比较复杂,大意就是让用户能够直接读写网卡的某些寄存器来实现和硬件的交互。这些映射到用户空间的寄存器中,最重要的就是Doorbell。它其实就是门铃的意思。是一种通知机制,当用户准备好WR之后,向Doorbell的地址中写一下数据,就等于敲了一下门铃,硬件就知道可以把WQE从QP中取走然后开始干活了。
* 挂载回调函数到IB框架
因为各个厂商的硬件和软件实现都不一样,所以IB框架开放了很多钩子函数,根据不同的硬件型号,会走到不同厂商的驱动程序中。
* 查询设备能力
用户可以获知当前硬件支持的功能、规格等信息,比如支持创建多少个QP,多少个CQ等等。
这个过程的调用栈如下图所示,这里仅列出了关键函数,红色虚线表示从用户态陷入内核态:
 #### ibv\_reg\_mr()
这个接口用来注册MR。MR以前的文章已经介绍过了,不再赘述,这一步主要完成了两件事:
* pin住内存
避免存放关键数据的内存被系统换页到硬盘中,导致数据收发过程中硬件读取内存不是用户所预期的。
* 建立虚拟地址和物理地址的映射表
只有建立好了表之后,硬件才能根据WQE中的虚拟地址找到实际的物理地址。
这一过程的调用栈如下图所示:
#### ibv\_reg\_mr()
这个接口用来注册MR。MR以前的文章已经介绍过了,不再赘述,这一步主要完成了两件事:
* pin住内存
避免存放关键数据的内存被系统换页到硬盘中,导致数据收发过程中硬件读取内存不是用户所预期的。
* 建立虚拟地址和物理地址的映射表
只有建立好了表之后,硬件才能根据WQE中的虚拟地址找到实际的物理地址。
这一过程的调用栈如下图所示:
 #### ibv\_create\_qp()
这个接口出镜很多次了,就是创建QP,具体主要完成了以下几件事:
* 校验并根据硬件能力修正QP参数
检测用户传入的创建参数是否合理,而因为硬件的限制,需要申请的规格可能会比用户需求的大,所以如果参数合理还会返回实际使用的参数给用户。
* 创建QP的相关资源
以前QP的文章介绍过,包括QPC、QPN等资源。
* 申请QP缓冲区
这里的缓冲区主要指存放SQ WQE和RQ WQE等的区域,即QP这个队列自己的内存空间。创建完之后,驱动会把QP的基地址告诉硬件,即让硬件知道上哪去找这个QP和它的属性。
这一过程的调用栈如下图所示:
#### ibv\_create\_qp()
这个接口出镜很多次了,就是创建QP,具体主要完成了以下几件事:
* 校验并根据硬件能力修正QP参数
检测用户传入的创建参数是否合理,而因为硬件的限制,需要申请的规格可能会比用户需求的大,所以如果参数合理还会返回实际使用的参数给用户。
* 创建QP的相关资源
以前QP的文章介绍过,包括QPC、QPN等资源。
* 申请QP缓冲区
这里的缓冲区主要指存放SQ WQE和RQ WQE等的区域,即QP这个队列自己的内存空间。创建完之后,驱动会把QP的基地址告诉硬件,即让硬件知道上哪去找这个QP和它的属性。
这一过程的调用栈如下图所示:
 #### 不需要陷入内核态的接口
不需要陷入内核的Verbs接口走的是左边红色箭头的”快路径“:
#### 不需要陷入内核态的接口
不需要陷入内核的Verbs接口走的是左边红色箭头的”快路径“:
 #### ibv\_post\_send()
这个接口也讲过几次了,功能就是用户下发WR给硬件。假设用户下发了一个SEND的WQE,这一过程具体完成了哪些工作呢:
* 从QP Buffer中获得下一个WQE的内存首地址(ibv\_create\_qp()中申请的)
* 根据与硬件约定好的结构,解析WR中的内容填写到WQE中
* 数据区域通过sge指定,sge指向的内存位于MR中(ibv\_reg\_mr()中注册的)
* 填写完毕,敲Doorbell告知硬件(地址是ibv\_open\_device()中映射得到的)
* 硬件从QP Buffer中取出WQE并解析其内容
* 硬件通过映射表(ibv\_reg\_mr()中建立的),将存放数据的虚拟地址转换成物理地址,取出数据
* 硬件组包、发送数据
从这个例子可以看出,**RDMA的所谓内核Bypass,并不是整个流程都绕过了内核,而是在控制路径多次进入内核进行准备工作,万事俱备之后,才可以在数据路径上避免陷入内核时的开销**。
#### ibv\_post\_send()
这个接口也讲过几次了,功能就是用户下发WR给硬件。假设用户下发了一个SEND的WQE,这一过程具体完成了哪些工作呢:
* 从QP Buffer中获得下一个WQE的内存首地址(ibv\_create\_qp()中申请的)
* 根据与硬件约定好的结构,解析WR中的内容填写到WQE中
* 数据区域通过sge指定,sge指向的内存位于MR中(ibv\_reg\_mr()中注册的)
* 填写完毕,敲Doorbell告知硬件(地址是ibv\_open\_device()中映射得到的)
* 硬件从QP Buffer中取出WQE并解析其内容
* 硬件通过映射表(ibv\_reg\_mr()中建立的),将存放数据的虚拟地址转换成物理地址,取出数据
* 硬件组包、发送数据
从这个例子可以看出,**RDMA的所谓内核Bypass,并不是整个流程都绕过了内核,而是在控制路径多次进入内核进行准备工作,万事俱备之后,才可以在数据路径上避免陷入内核时的开销**。