😇LSM Tree
目前
HBase,LevelDB,RocksDB这些NoSQL存储都是采用的LSM树利用顺序写来提高写性能
将所有的增删查改操作记录存入内存,一定数量之后批量写入磁盘,更新数据时直接append一条更新记录(顺序写),不去修改之前的key。(B+树数据的更新会直接在原数据所在处修改对应的值)
读性能低:分层(内存和文件)以读性能作为trade-off换取写性能
sstable以SST简写代替
core idea
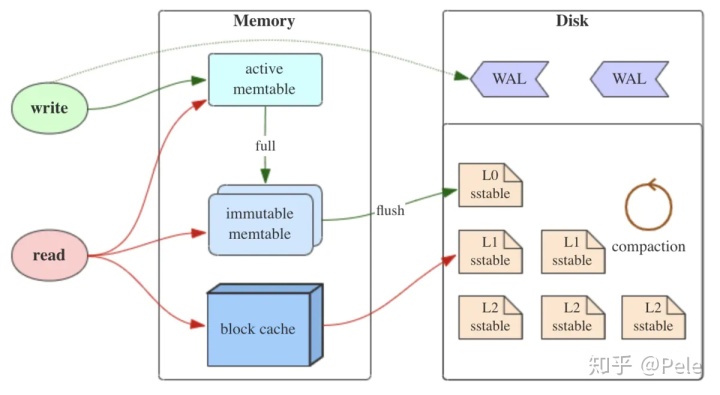
MemTable
内存中的DS(定义自便),按键值有序组织最近更新的数据
非可靠存储,需要WAL(预写式日志)方式保存可靠性(执行写操作时,先同时写memtable与预写日志WAL)
Immutable MemTable
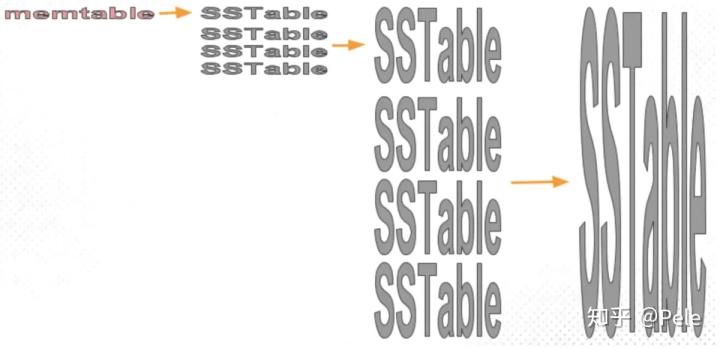
Memtable -> Immutable MemTable -> SSTable
中间状态,写操作由新的memtable处理,转存中不会阻塞数据更新
(memtable写满后会自动转换成不可变的(immutable)memtable,并flush到磁盘,形成L0级sstable文件)
Sorted String Table
有序键值对组合,树在磁盘中的DS
加快读取:建立key的索引和布隆过滤器加快查找key
执行读操作时,会首先读取内存中的数据(根据局部性原理,刚写入的数据很有可能被马上读取),即memtable→immutable memtable→block cache。如果内存无法命中,就会遍历L0层sstable来查找。如果仍未命中,就通过二分查找法在L1层及以上的sstable来定位对应的key
随着sstable的不断写入,系统打开的文件就会越来越多,并且对于同一个key积累的数据改变(更新、删除)操作也就越多。由于sstable是不可变的,为了减少文件数并及时清理无效数据,就要进行compaction操作,将多个key区间有重合的sstable进行合并。本文暂无法给出"compaction"这个词的翻译,个人认为把它翻译成“压缩”(compression?)或者“合并”(merge?)都是片面的。
当MemTable达到一定大小flush到持久化存储变成SSTable后,在不同的SSTable中,可能存在相同Key的记录,当然最新的那条记录才是准确的。这样设计的虽然大大提高了写性能,但同时也会带来一些问题:
冗余存储:某个key只有最新的有用,需要使用compact合并多个和sstable清除冗余记录
读取时由最新的倒着查,最坏情况需要查完整个sstable,索引/布隆过滤器来优化查找速度
compact strategy
三大概念
读放大:实际读取数量 > 真正数据量(eg:查memtable再查sstable)
写放大:实际写入数量 > 真正数据量(eg:写入时触发compact操作)
空间放大:实际占用磁盘空间 > 真正大小(eg:冗余存储)
两个策略
size-tiered strategy
每层sstable大小相近,同时限制每一层sstable的数量N, 达到N后触发compact合并成为一个更大的sstable到下一层
优点是简单且易于实现,并且SST数目少,定位到文件的速度快。当然,单个SST的大小有可能会很大,较高的层级出现数百GB甚至TB级别的SST文件都是常见的。
空间放大很严重,同一层的sstable,每一个key可能存在多份,直到该层执行compact合并消除冗余
但是重复key过多,就算每层compact过后消除了本层的空间放大,但key重复的数据仍然存在于较低层中,始终有冗余。只有手动触发了full compaction,才能完全消除空间放大,但我们也知道full compaction是极耗费性能的。
leveled
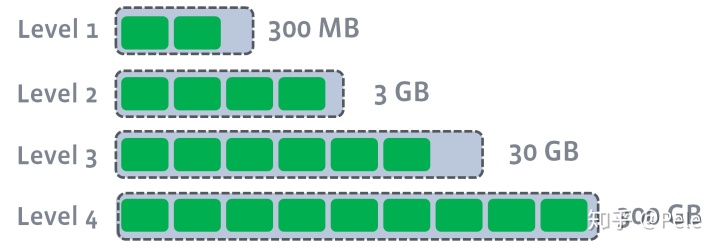
分层(顶层在上底层在下),每一层限制总文件的大小
对于L1层及以上的数据,将size-tiered compaction中原本的大SST拆开,成为多个key互不相交的小SST的序列,这样的序列叫做“run”。L0层是从memtable flush过来的新SST,该层各个SST的key是可以相交的,并且其数量阈值单独控制。从L1层开始,每层都包含恰好一个run,并且run内包含的数据量阈值呈指数增长
每一层切分成大小相近的sstable,全局有序,key在本层不存在冗余记录
合并策略不同于上一个:
如果L1总大小超过本层限制,从L1中选择至少一个文件,把它跟L2的交集合并,生成文件放入L2,同时L1相关数据删除
如此重复下去
多个不相干的层的合并可以并发进行
相较于size-tiered,leveled每层的key不重复,即使最坏情况(除了最底层,其余都是重复key),冗余占比也很小,空间放大问题得到缓解
但是写放大问题突出:Ln层SST在合并到Ln+1层时是一对多的,故重复写入的次数会更多。最坏情景,第N层某个sstable的key跨很大,覆盖了N+1层的所有key,故合并的时候写入量很大
RocksDB的compaction策略✔
RocksDB的写缓存(即LSM树的最低一级)名为memtable,对应HBase的MemStore;读缓存名为
block cache,对应HBase的同名组件
由于上述两种compaction策略都有各自的优缺点,所以:
RocksDB在L1层及以上采用leveled compaction,而在L0层采用size-tiered compaction。
当L0层的文件数目达到level0_file_num_compaction_trigger阈值时,就会触发L0层SST合并到L1
>= L1
leveled compaction策略中每一层的数据量是有阈值的,那么在RocksDB中这个阈值该如何确定呢?需要分两种情况来讨论。
参数
levle_compaction_dynamic_level_bytes= falseL1的阈值由参数
max_bytes_for_level_base确定,单位为字节余层递推:
target_size(Lk+1) = target_size(Lk) * max_bytes_for_level_multiplier * max_bytes_for_level_multiplier_addition[k]
max_bytes_for_level_multiplier是固定的倍数因子max_bytes_for_level_multiplier_additional[k]是第k层对应的可变倍数因子参数
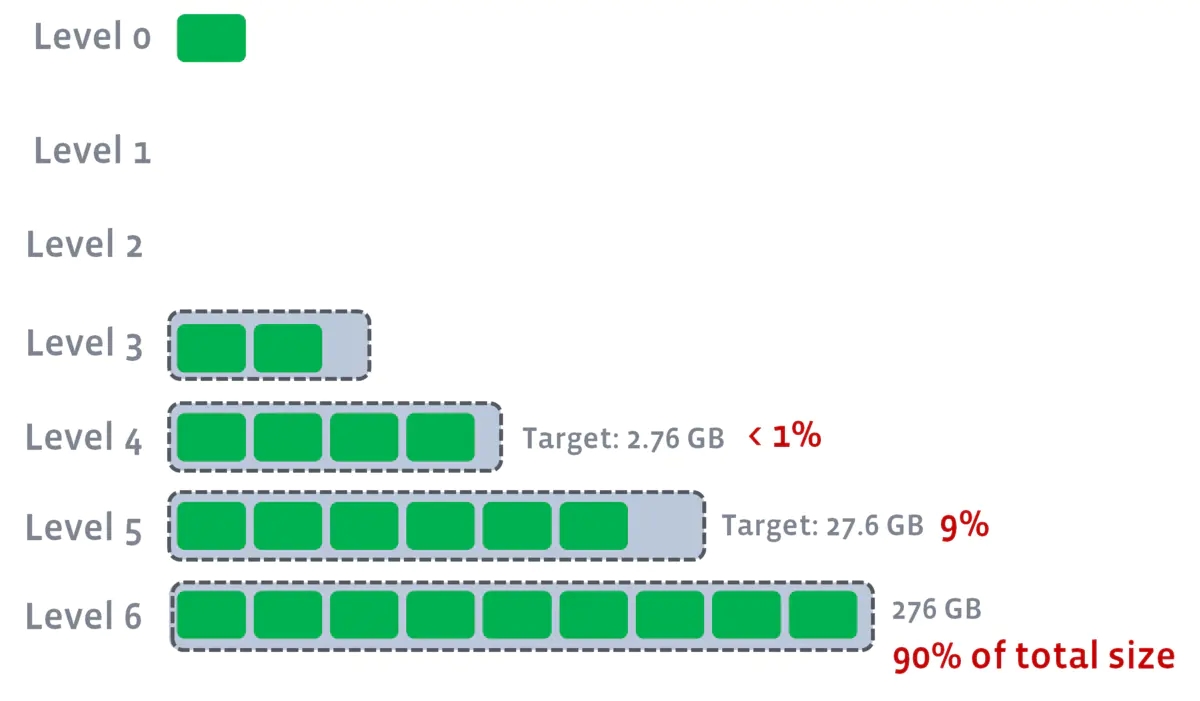
levle_compaction_dynamic_level_bytes= true最高一层的大小不设阈值限制,亦即target_size(Ln)就是Ln层的实际大小
而更低层的大小阈值会满足如下的倒推关系:
target_size(Lk-1) = target_size(Lk) / max_bytes_for_level_multiplier
max_bytes_for_level_multiplier的作用从乘法因子变成了除法因子。特别地,如果出现了target_size(Lk) < max_bytes_for_level_base / max_bytes_for_level_multiplier的情况,那么这一层及比它低的层就都不会再存储任何数据。
= L0 (universal compaction)
universal compaction是RocksDB中size-tiered compaction的别名,专门用于L0层的compaction,因为L0层的SST的key区间是几乎肯定有重合的
当L0层的文件数目达到level0_file_num_compaction_trigger阈值时,就会触发L0层SST合并到L1。universal compaction还会检查以下条件:
空间放大比例:
假设
L0层现有的SST文件为(R1, R1, R2, ..., Rn),其中R1是最新写入的SST,Rn是较旧的SST。空间放大比例 = L0层文件总大小 / Rn大小
若比值 >
max_size_amplification_percent / 100,将L0层所有的SST进行合并相邻文件大小比例:
参数
size_ratio用于控制相邻文件大小比例的阈值直到不再满足上述条件为止
若上述两个条件都没有触发compaction,该策略就会线性地从R1开始合并,直到L0层文件数小于level0_file_num_compaction_trigger阈值
Last updated