😚General
组成架构与原理介绍
Basic
先放一个RocksDB官方博客
首先放一个组成和操作流程的图:
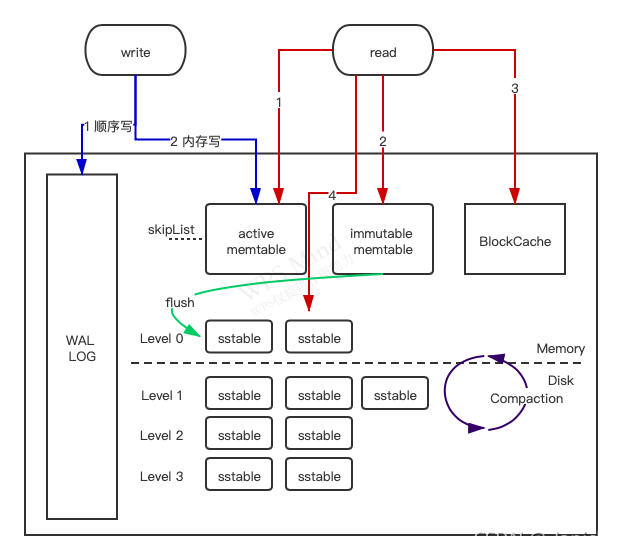
一些零星小点:
memtable:
为了保证数据的有序性,数据插入搜索的高效性
O(log n),MemTable基于skipList实现,还可以选择HashLinkList、HashSkipList、Vector用来加速某些查询:SkipList MemTable为读写、随机访问和顺序扫描提供了总体良好的性能,还提供了其他 memtable 实现目前不支持的一些其他有用功能,例如并发插入和带
Hit插入HashSkipList MemTableHashSkipList将数据组织在哈希表中,每一个哈希桶都是一个有序的SkipList,key是原始key通过Options.prefix_extractor截取的前缀key。主要用于减少查询时的比较次数。一般与
PlainTable SST格式配合使用将数据存储在 RAMFS 中。基于哈希的 memtables 的最大限制是跨多个前缀进行扫描需要复制和排序,非常慢且内存成本高。
WAL用于故障发生时的数据恢复,可选择关闭。
每个SSTable除了包含数据块(DataBlock)外,还有一个索引块(IndexBlock)用于二分查找
触发 Memtable 刷新落盘的场景:
写入后 Memtable 大小超过
ColumnFamilyOptions::write_buffer_size所有列族的 Memtable 用量超过
DBOptions::db_write_buffer_size或者write_buffer_manager发出刷新信号。最大的 MemTable 将会 flushedWAL文件大小超过
DBOptions::max_total_wal_size
Block Cache:
RocksDB 在内存中缓存数据以供读取的地方:
最近,高频访问的数据存储在Block Cache中;
其次依次按照写入最新时间查找MemTable;
再其次按从磁盘中的Level 0依次往后查找到SST文件;
根据查找的KEY 判断是否在SST的min_key和max_key中间;
布隆过滤器判断如果KEY不在,则查找下一个SST文件,如果数据在该SST文件,则二分法查找;
一个Cache对象可以被同一个进程中的多个RocksDB实例共享,用户可以控制整体的缓存容量。
存储未压缩的块。
用户可以选择设置存储压缩块的二级块缓存。
读取将首先从未压缩的块缓存中获取数据块,然后是压缩的块缓存。
如果使用
Direct-IO,压缩块缓存可以替代 OS 页面缓存。Block Cache有两种缓存实现,分别是
LRUCache和ClockCache。两种类型的缓存都使用分片以减轻锁争用。容量平均分配给每个分片,分片不共享容量。默认情况下,每个缓存最多会被分成 64 个分片,每个分片的容量不小于 512k 字节。LRUCache: 默认的缓存实现。使用容量为8MB的基于LRU的缓存;
缓存的每个分片都维护自己的LRU列表和自己的哈希表以供查找。通过每个分片的互斥锁实现同步,查找与插入都需要对分片加锁。
极少数情况下,在块上进行读或迭代的,并且固定的块总大小超过限制,缓存的大小可能会大于容量。
如果主机没有足够的内存,这可能会导致意外的 OOM 错误,从而导致数据库崩溃。
ClockCache: ClockCache 实现了CLOCK 算法。时钟缓存的每个分片都维护一个缓存条目的循环列表。
时钟句柄在循环列表上运行,寻找要驱逐的未固定条目,但如果自上次扫描以来已使用过,也给每个条目第二次机会留在缓存中。
ClockCache 还不稳定,不建议使用

Write Buffer Manager:
用于控制多个列族或者多个数据库实例的内存表总使用量。
使用方式:用户创建一个write buffer manager对象,并将对象传递到需要控制内存的列族或数据库实例中。
有两种限制方式:
1、限制 memtables 的总内存用量
触发其中一个条件将会在实例的列族上触发flush操作:
如果活跃的 memtables 使用超过阈值的90%
总内存超过限制,活跃的 mamtables 使用也超过阈值的 50% 时。
2、memtable 的内存占用转移到 block cache
大多数情况下,block cache中实际使用的block远小于block cache中缓存的,所以当用户启用该功能时,block cache容量将覆盖block cache和memtable两者的内存使用量。
如果用户同时开启 cache_index_and_filter_blocks,那么RocksDB的三大内存区域(index and filter cache, memtables, block cache)内存占用都在block cache中。
SSTable:
默认表格式:BlockBaseTable
具体类型与LevelDB无区别:
DataBlock (数据块):键值对序列按照根据排序规则顺序排列,划分为一系列数据块(data block)。这些块在文件开头一个接一个排列,每个数据块可选择性压缩。
MetaBlock (元数据块) :紧接着数据块,元数据块包括:过滤块(
filter block)、索引块(index block)、压缩字典块(compression dictionary block)、范围删除块(range deletion block)、属性块(properties block)。具体来讲:
filter block:
bloom filter实现全局过滤器 Full Filter: 在此过滤器中,整个 SST 文件只有一个过滤器块。
分区过滤器 Partitioned Filter: Full Filter 被分成多个子过滤器块,在这些块的顶层有一个索引块用于将key映射到相应的子过滤器块。
Compression Dictionary Block:包含用于在压缩/解压缩每个块之前准备压缩库的字典。
range deletion block:包含文件中key 与 序列号中的删除范围。在读请求下发到sst的时候能够从sst中的指定区域判断key是否在deleterange 的范围内部,存在则直接返回NotFound。
memtable中也有一块区域实现同样的功能。
compaction或者flush的时候会清除掉过时的tombstone数据。
properties block:每种属性都是一个键值对
data size:data block总大小index size:index block总大小filter size:filter block总大小raw key size:所有key的原始大小raw value size:所有value的原始大小number of entriesnumber of data blocks
MetaIndexBlock (元索引块) : 元索引块包含一个映射表指向每个meta block,key是meta block的名称,value是指向该meta block的指针,指针通过offset、size指向数据块。
Footer (页脚) :文件末尾是固定长度的页脚。包括指向metaindex block的指针,指向index block(metablock中)的指针,以及一个magic number。
Column Family:

可以将数据的键值对按照不同的属性分配给不同的CF,可以让某些内存和SST文件中存的都是相同类型的数据,可以极大地增加读写的效率、提升数据压缩率;
落数的时候会自带CF1、CF2、default 来决定落入哪个分片中;
内存和SST文件都按照CF分了,但是WAL没有按照CF区分
Last updated